3.8万小时、狂烧天价token:字节发现Agent的 Scaling Law
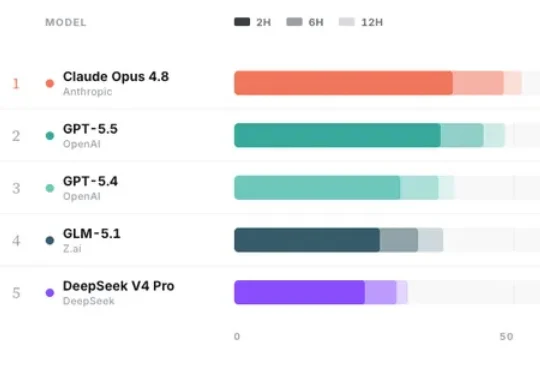
3.8万小时、狂烧天价token:字节发现Agent的 Scaling Law7月2日,字节 Seed 发布了一个 Agent评测项目 EdgeBench。看起来又是一个 benchmark,但它问了一个其他榜单不问的问题。EdgeBench 的切口就是把盲区里的东西放进评测,解答一个问题:把Agent扔进一个陌生环境,12小时后,你能变强多少?
来自主题: AI技术研报
8448 点击 2026-07-08 15:53